从零到一:我在Flutter中构建EPUB阅读器的趟坑实录
前言
作为一个小说爱好者,阅读对我来说不仅是打发时间,更是一种能让我沉浸在另一个世界里的方式。每次翻页,都像是短暂地逃离现实,投入到文字编织的世界里。
正因为这样,我突然有了个想法:为什么不自己动手做一个专属的 EPUB 阅读器呢?
这样不仅能顺便深入研究一下 Flutter 的渲染机制,还能给自己打造一个完全属于我的阅读空间。带着这样的念头,我就开始了这段既有挑战又充满乐趣的旅程。
从最开始的一个小小念头,到一步步把功能做出来,最终有了 DReader —— 一个简易的 EPUB 阅读器。对我来说,它不仅仅是个项目,更是我把对阅读的热爱和技术探索结合在一起的成果。
技术选型
在项目初期,我尝试了多种针对该EPUB书籍的渲染方案,每种方案都具备其独特的优势。
方案一:提取文本,自行排版
- 我的初衷是将 EPUB 文件中的所有文本提取出来,交由 Flutter 重新计算排版,并对图片进行单独处理,从而实现阅读器的渲染。然而,在实际实现中却遇到了许多棘手问题:排版效果十分怪异,对于部分特殊标签无法很好地兼容。例如,一个注释图标可能会被渲染成占据整整一页。最终,这种“自排版”方案因体验不佳而被弃用。
方案二:WebView 渲染
- 由于 EPUB 本质上是由一组 XHTML 文件构成,直接使用 WebView 来渲染无疑是最简单、最还原原始样式的方式。这一方案的优势在于实现成本低,能最大程度保持原书的样式和排版。但它的缺陷也十分明显:HTML 的渲染是自上而下的线性布局,要在 WebView 中实现原生般的左右翻页效果并不容易。权衡再三,这一方案也被我放弃
方案三:基于 Canvas 的自研渲染引擎(最终方案)
- 这是 DReader 最终采用的实现方式。该方案的核心思想是:解析 EPUB 文件中的 XHTML、CSS、图片等资源,并将它们转换为 Flutter 可渲染的控件,相当于在 Flutter 的画布上“重新绘制”页面。相较于 WebView,这种方式虽然实现难度更高,但优势在于高度可控与可定制化。比如我最喜欢的左右翻页的功能,在自绘制的模式下就能非常自然地实现。
EPUB 文件结构
在实现项目的前提下首先需要了解的就是这个 EPUB 文件到底是个什么东西,EPUB 本质上是一个压缩包(后缀名 .epub),内部包含书籍的所有内容和资源。其目录结构大致如下图所示
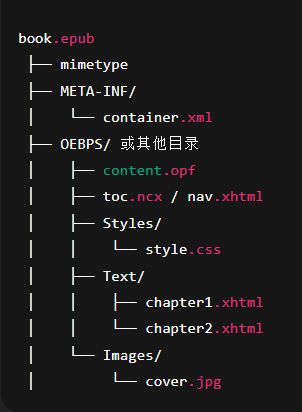
关键的文件说明
mimetype:必须存在,且内容固定为application/epub+zip。用于声明文件是 EPUB 格式。META-INF/container.xml:指定书籍的入口 .opf 文件路径*.opf:EPUB 的核心清单文件,定义了 资源文件、章节顺序、元信息*.xhtml:书籍的实际正文,每一章通常是一个 XHTML 文件。*.css:定义书籍的排版和样式toc.ncx / nav.xhtml:目录文件(EPUB 2 用 toc.ncx,EPUB 3 用 nav.xhtml),主要作用是用于生成章节导航
EPUB 文件工作流程
container.xml
告诉阅读器.opf文件的位置.opf
定义 书籍的元信息、资源清单和阅读顺序.xhtml+.css+ 图片
构成书籍的 实际展示内容
EPUB 文件解析
要实现阅读功能,首要步骤是将 EPUB 文件解析出来。这意味着,我们需要将 EPUB 内部的 XHTML、CSS 等文件,通过 Dart 语言转换为程序可以理解的元数据。
读取并解压 EPUB 文件
遵循 EPUB 的标准工作流程,解析的获取到EPUB文件中的所有的文件。
具体的实现方式是:首先将整个 EPUB 文件(本质是 ZIP 压缩包)解压,然后将内部所有文件存入一个
Map中。在这个Map里,key是文件名(例如META-INF/container.xml),value则是对应文件的二进制数据流。📄查看代码
// 这里传入进来的是EPUB文件的二进制流 Future<Map<String, List<int>>> extractEpubFromBytes(List<int> epubBytes) async { final archive = ZipDecoder().decodeBytes(epubBytes); final extractedFiles = <String, List<int>>{}; for (final file in archive) { if (file.isFile) { extractedFiles[file.name] = file.content as List<int>; } } return extractedFiles; }解析 META-INF/container.xml 获取 .opf 文件
对于拿到的
Map中去找到这个文件META-INF/container.xml并使用XmlDocument去解析这个xml文件拿到rootfiles标签的full-path属性以获取.opf文件的位置📄查看代码
// 这里传入进来的是在解析EPUB文件时获取到的所有文件资源 String locateOpfFile(Map<String, List<int>> files) { const containerPath = 'META-INF/container.xml'; if (!files.containsKey(containerPath)) { throw Exception('container.xml not found!'); } final containerContent = utf8.decode(files[containerPath]!); final document = XmlDocument.parse(containerContent);//解析container.xml //拿到对应的rootfile标签下的full-path属性的值 final opfPath = document.findAllElements('rootfile').first.getAttribute('full-path'); if (opfPath == null) { throw Exception('OPF file path not found in container.xml!'); } //这里在获取这个opf的父级文件夹 _opfDir = opfPath.contains("/") ? opfPath.substring(0, opfPath.lastIndexOf("/")) : ""; return opfPath; }解析 .opf 文件以获取资源文件及章节顺序
拿到对应的
.opf文件后就可以处理出来这些资源文件以及章节的顺序了📄查看代码
// 这里传入进来的是在解析处理好的opf文件的内容 Map<String, dynamic> parseOpf(String opfContent) { final document = XmlDocument.parse(opfContent); // 解析 manifest Map<String, String> manifest = {}; for (final item in document.findAllElements('item')) { final id = item.getAttribute('id'); final href = item.getAttribute('href'); if (id != null && href != null) { manifest[id] = href; } } // 解析 spine final spine = document .findAllElements('itemref') .map((itemRef) { return itemRef.getAttribute('idref'); }) .where((idref) => idref != null) .toList(); return {'manifest': manifest, 'spine': spine}; }编排并返回资源文件
按照
spine中的循序排好章节,并将其返回出来📄查看代码
// 这里传入进来的是处理好的manifest(资源文件)和spine(排序) List<String> readChapters(Map<String, List<int>> files,Map<String, String> manifest,List<String?> spine,) { final chapters = <String>[]; for (final idref in spine) { String? relativePath = manifest[idref]; if (relativePath == null) { throw Exception('Warning: idref $idref not found in manifest.'); } relativePath = Uri.decodeFull(relativePath); final chapterFile = files["$_opfDir/$relativePath"]; if (chapterFile == null) { throw Exception('Warning: Chapter file not found: $relativePath'); } final content = utf8.decode(chapterFile); chapters.add(content); } return chapters; }
CSS 文件解析与样式重写
在成功解析并提取出 EPUB 文件的基础资源之后,接下来的重点就是对 CSS 文件 的处理。
众所周知,EPUB 本质上就是一组 XHTML + CSS 的组合文件,因此要在 Flutter 中复现 EPUB 的样式效果,就必须解决 如何让 Flutter 正确理解并渲染 CSS 样式 这个问题。
在项目中,我选择了使用 csslib 这个库来解析 CSS。它能够帮助我把 EPUB 中的 CSS 文件解析为 Dart 结构化数据,接着我再将其规则重写为 Flutter 可使用的 TextStyle,以实现样式的映射。
为了模拟 CSS 的优先级机制,我设计了四类样式集合:
tagStyles—— 针对标签选择器,例如p、h1classStyles—— 针对类选择器,例如.highlightidStyles—— 针对 ID 选择器,例如#titlecomplexStyles—— 针对复合选择器,例如p.note
通过这几类样式集合,就可以实现一个简易版的「样式层叠与覆盖」逻辑,从而保证不同来源的样式不会互相冲突。
目前项目只实现了对 EPUB 中常用 CSS 属性的支持,例如:
margin—— 外边距padding—— 内边距line-height—— 行高font-size—— 字体大小
换句话说现在的样式系统还不足以完全还原 EPUB 的排版效果,但已经能应付大多数基础的阅读需求。
📌 具体的实现细节可以在源码文件 CssToTextstyle.dart 中查看。
解析DOM 获取节点树
在完成对所有 CSS 文件 的解析之后,接下来就进入 XHTML 文件的解析阶段。
众所周知,一个 HTML 文件通常由一个 <body> 节点包裹住其内部的所有 DOM,而 DOM 之间又可能存在嵌套关系。这种嵌套式的 DOM 结构,最终构成了我们日常看到的网页布局。
因此,在解析 XHTML 文件时,我同样保留了这种 嵌套 DOM 的层级结构,以便后续在渲染阶段能够正确地还原出 DOM 之间的排版关系。
在解析 XHTML 文件时,我使用了 html 库来完成对 DOM 节点的解析。 html 库可以将 XHTML 内容转换为 Dart 的 DOM 对象,方便后续的递归遍历和节点树构建。
其中这里面的这些 Node 类,都是对应的 DOM 实现节点类,具体细节会在 下一个章节 中展开说明。
以下是我对 XHTML DOM 节点的处理逻辑:
// 参数说明:
// nodes —— 当前节点下的子节点列表
// baseStyle —— 当前节点已有的样式
// useCss —— 当前使用到的 CSS 文件集合
Future<List<ReaderNode>> domParse(List<dom.Node> nodes, ModelStyle baseStyle, List<String> useCss) async {
List<ReaderNode> list = [];
for (var node in nodes) {
ReaderNode readerNode;
// 拷贝父级样式,作为当前节点的基础样式
ModelStyle style = baseStyle.clone();
//判断是否为文本节点,如果为文本节点就可以直接添加到这个List<ReaderNode> list中
//文本节点就是不会存在子节点
if (node is dom.Text) {
String text = node.text;
text = text.replaceAll('\n', '').trim(); //去除掉文本中的'\n'换行符
if (text.isNotEmpty) {
list.add(TextNode(TextSpan(text: text, style: style.textStyle), style, nodeIndex));
}
}
// 元素节点:可能包含子节点,需要进一步解析
else if (node is dom.Element) {
//判断使用了那些css文件,将对应的样式匹配到当前的ModelStyle中
for (String css in useCss) {
style = getStyle(css, style, node);
}
//行内样式应为不在css文件中所以需要单独的处理
String? nodeStyle = node.attributes["style"];
if (nodeStyle != null) {
style = style.merge(cssToTextstyle.parseInlineStyle(nodeStyle));
}
//HTML中的节点分为inline(行内)和block(块级)
if (blockList.contains(node.localName)) {
readerNode = BlockNode(node.localName!, style, nodeIndex);
} else {
if (["image", "img"].contains(node.localName)) {
String? path = getImageBytes(node);
if (path == null) continue;
List<int>? list = epubParsing.getImage(path);
if (list == null || list.isEmpty) continue;
readerNode = ImageNode(node.localName!, style, nodeIndex, list, path);
await (readerNode as ImageNode).decode();
} else if (node.localName == "i") {
readerNode = INode("i", style, nodeIndex);
} else if (node.localName == "ruby") {
readerNode = RubyNode("ruby", style, nodeIndex);
} else if (node.localName == "rt") {
readerNode = RtNode("rt", style, nodeIndex);
} else if (node.localName == "br") {
readerNode = BrNode("br", style, nodeIndex);
} else if (node.localName == "del") {
readerNode = DelNode("del", style, nodeIndex);
} else if (node.localName == "b") {
readerNode = BNode("b", style, nodeIndex);
} else {
readerNode = InlineNode(node.localName!, style, nodeIndex);
}
}
//在readerNode有做特殊处理可能要继承到子节点中
style = readerNode.styleModel;
//递归解析子节点
readerNode.children = await domParse(node.nodes, style, useCss);
// 加入结果列表
list.add(readerNode);
}
nodeIndex++;
}
return list;
}当 domParse 方法执行完成后,会得到一个 树形结构的节点树,该结构完整保留了 XHTML 中的层级与排版关系。
为了便于后续的 分页渲染,需要将这个节点树保存起来,作为后续渲染的基础数据。
...省略部分代码
List<ReaderNode> nodeList = await domParse(document.body?.nodes ?? [], ModelStyle(), useCss);
if (nodeList.length > 1) {
BodyNode bodyNode = BodyNode();
bodyNode.children = nodeList;
nodeListList.add([bodyNode]);
} else {
nodeListList.add(nodeList);
}
...省略部分代码ReaderNode 设计
在 EPUB 阅读器的实现中,最核心的部分就是 将解析后的 XHTML DOM 节点映射为 Flutter 可渲染的节点树。
为此,我设计了一套 ReaderNode 抽象类 及其子类,用来承载 DOM 的 语义、样式、排版和绘制逻辑。
核心思想
- 每一个
ReaderNode对应着一个 DOM 节点,负责存储该节点的 样式信息、布局位置、大小 以及 子节点树。 - 这样,解析后的 XHTML 节点树就能直接参与到分页排版与渲染中。
关键方法
layout:负责计算节点在页面中的布局(位置、高度、宽度),以及是否需要分页或换行。paint:负责将节点绘制到Canvas上。deepUpdateOffset:用于同一行内的节点对齐(如垂直居中)。
ReaderNode 抽象类
abstract class ReaderNode {
static int page = 0;
static List<List<ReaderNode>> list = [];
List<ReaderNode> children = []; //子节点列表
late ModelStyle styleModel;//样式
bool isTurning;//判断该节点是否需要分分页
bool isEnter;//判断该节点是否需要分行
bool isBranch = true;//节点是否允许分行
double? remainingHeight;//当前页面剩余高度
Offset currentOffset = const Offset(0, 0);//该节点绘制的位置
Offset? nextOffset;//下一个节点绘制的位置
double currentHeight = 0;//当前节点的高度
double currentWidth = 0;//当前节点的宽度
int uniqueId;//节点的唯一ID
bool isCurrent = false;
List<int> hasIndexList = [];//该节点包括其子节点的uniqueId
ReaderNode(this.styleModel, this.uniqueId,{this.isTurning = false, this.isEnter = false});
//布局前的操作
void layoutBefore() {
hasIndexList = [uniqueId];
isTurning = false;
isEnter = false;
}
//布局方法交由子类实现
List<ReaderNode> layout(double availableWidth, Offset offset,{isFull = true});
//绘制方法交由子类实现
void paint(Canvas canvas, Offset offset);
//该方法主要用于同一行内的所有节点垂直居中
void deepUpdateOffset(double dxDifference, double dyDifference) {
for (var element in children) {
element.deepUpdateOffset(dxDifference, dyDifference);
}
currentOffset = Offset(currentOffset.dx + dxDifference, dyDifference + currentOffset.dy);
if (nextOffset != null) {
nextOffset = Offset(nextOffset!.dx + dxDifference, dyDifference + nextOffset!.dy);
}
}
ReaderNode clone() {
return this;
}
}通过继承这个方法去实现布局与绘制的功能,下面是两个最重要的实现类,
TextNode 类
TextNode 类继承自 ReaderNode 抽象类,主要用于 绘制文本。
它的核心功能是借助 Flutter 的 TextPainter 来完成文本的 布局计算 与 渲染绘制。
在 layout 方法中,TextNode 负责以下工作:
- 当
availableWidth(可用宽度)不足时,对文本进行 切割换行。 - 当文本高度超过
remainingHeight(页面剩余高度)时,对文本进行 分页截断。 - 计算节点的 位置 (Offset)、高度、宽度,并生成下一节点的起始坐标。
📄查看代码
class TextNode extends ReaderNode {
TextSpan textSpan;//在解析Dom时传入的文本内容
TextPainter? textPainter;
List<ReaderNode> listNode = [];//返回出去交由ElementNode处理的集合
TextNode(
this.textSpan,
super.styleModel,
super.uniqueId
);
//当这里的textPainter不为null的时候就可以直接绘制这个文本到画布上了
@override
void paint(Canvas canvas, Offset offset) {
if (textPainter != null) {
textPainter!.paint(canvas, offset);
}
}
// 布局方法:计算文本的宽高、分页逻辑、换行逻辑
@override
List<ReaderNode> layout(double availableWidth, Offset offset, {isFull = true}) {
layoutBefore();
// 初始化 TextPainter
textPainter = TextPainter(text: textSpan, textDirection: TextDirection.ltr);
textPainter!.layout(maxWidth: availableWidth);
currentOffset = offset;
double lastWidth = 0;//最后一行的宽度,以方便计算
//判断是否为开头
if (!isFull) {
//如果不是开头的话(意及改行中有其他的节点存在)
// 获取在最大宽度处的文本位置
TextPosition pos = textPainter!.getPositionForOffset(Offset(availableWidth, 0));
final splitIndex = pos.offset;
if (splitIndex != textSpan.text!.length) {
//该行放不下所有的文本,将分行标记为true等待ElementNode处理
isEnter = true;
if (splitIndex == 0 || (splitIndex < textSpan.text!.length && !isBranch)) {
segmentation(0,0);
return listNode;
}
segmentation(splitIndex, availableWidth);
}
}
//通过computeLineMetrics方法来获取到文本布局的详细行度量信息
List<LineMetrics> list = textPainter!.computeLineMetrics();
if (list.isEmpty) return [];
lastWidth = list.last.width;
//当文本的高度大于页面剩余高度就要开始处理分页的问题
if (textPainter!.height > remainingHeight!) {
int endOffset = 0;
double totalHeight = 0;
for (LineMetrics lineMetrics in list) {
totalHeight += lineMetrics.height;//将每一行文本的高度相加
if (totalHeight > remainingHeight!) break;
//这里的计算时因为考虑到文本不可能每一行都可以完完全全的占满,最后一行有可能有剩余的宽度可以给到下一个节点使用,但是如果直接拿取textPainter的宽度的话,是直接拿到整个文本的宽度,而不是最后一行的宽度,所以这里要将这个最后一行的宽度计算出来
final lineEndOffset = textPainter!.getPositionForOffset(Offset(lineMetrics.left + lineMetrics.width, lineMetrics.baseline)).offset;
lastWidth = lineMetrics.width;
endOffset = lineEndOffset;
}
//将分页标记改为true
isTurning = true;
segmentation(endOffset, availableWidth);
}
double dx = list.last.width + currentOffset.dx;//计算下一个节点的在X轴上的位置
double dy = currentOffset.dy + textPainter!.height - list.last.height;//计算下一个节点的在Y轴上的位置
currentHeight = textPainter!.height;
currentWidth = textPainter!.width;
nextOffset = Offset(dx, dy);
return listNode;
}
//
void segmentation(int index, double maxWidth) {
String remainingText = textSpan.text!.substring(index);
TextSpan newTextSpan = TextSpan(text: remainingText, style: textSpan.style);
TextNode newTextNode = TextNode(newTextSpan, styleModel,uniqueId);
listNode.insert(0, newTextNode);
String currentText = textSpan.text!.substring(0, index);
textSpan = TextSpan(text: currentText, style: textSpan.style);
textPainter = TextPainter(text: textSpan, textDirection: TextDirection.ltr);
textPainter!.layout(maxWidth: maxWidth);
}
}ElementNode 类
ElementNode 继承自 ReaderNode,是渲染器中 负责整体布局与排版的核心节点。
由于 DOM 解析后的内容会被组织为 ReaderNode 树,最终所有节点的排版与分页逻辑,都会在 ElementNode 的 layout 方法中被统一调度与处理。
它的主要职责包括:
- 子节点排版管理:逐个对子节点调用
layout,并根据行内/块级特性进行布局。 - 分页逻辑控制:当当前页剩余高度不足时,触发分页并克隆自身,以保持树结构的完整性。
- 块级与行内元素区分:
- 块级元素独占一行,会处理外边距与内边距。
- 行内元素则会参与同一行的排版,并自动对齐调整。
- 行内高度对齐:若同一行内的节点高度不一致,会通过
rearrangement方法重新调整偏移,保证视觉对齐。 - 递归渲染:在
paint阶段会递归调用子节点的paint,最终完成整页内容的绘制。
因此,ElementNode 可以理解为 ReaderNode 树的“版面调度器”,它不仅负责管理子节点的位置与分页,还保证了整棵渲染树在视觉和逻辑上的一致性。
此外,还有一些类继承自 ElementNode,它们可能会重写 layout 方法以实现更特殊的布局逻辑。
但在这里不展开说明,ElementNode 是渲染器中扮演布局重任的核心类,是整个 ReaderNode 树最终排版的调度器。
📄查看代码
class ElementNode extends ReaderNode {
String tag; //标签
ElementNode(
this.tag,
super.styleModel,
super.uniqueId,
);
double defaultDx = 0;
double defaultDy = 0;
bool isOver = true; //判断该节点是否完成了
List<ReaderNode> truncatedNode = [];//拿取裁断分页节点
List<ReaderNode> nextPageNode = [];//本页放不下要到下页渲染的节点集合
double currentLineHeight = 0;//当前行的高度
double currentLineWidth = 0;//当前行的宽度
int truncatedIndex = -1;
List<int> currentLineIndex = []; //当前行含有的所有子节点下标
bool highlyInconsistent = false;//判断是否垂直居中
@override
List<ReaderNode> layout(double availableWidth, Offset offset, {isFull}) {
layoutBefore();
currentOffset = offset;
remainingHeight ??= NodeStatus.pageHeight;//当remainingHeight为空则直接那当前的页面的高度作为剩余高度
defaultDx = offset.dx;
double top = 0;
//判断如果为块级元素则要加上这个外边距和内边距的实现
if (this is BlockNode) {
void applyEdgeInsets(EdgeInsets? insets) {
if (insets == null) return;
availableWidth -= insets.left + insets.right;
defaultDx += insets.left;
if (insets.top != 0 && isOver) {
top += insets.top;
}
}
applyEdgeInsets(styleModel.margin);
applyEdgeInsets(styleModel.padding);
}
//将高度和默认位置的y轴加上对应的外边距和内边距上边的值
defaultDy = offset.dy + top;
currentHeight += top;
//判断果然当前的位置以及高出页面的高度以及这个节点还存在子节点就直接分页
if (defaultDy >= NodeStatus.pageHeight && children.isNotEmpty) {
isTurning = true;
}
if (isTurning) {
//需要分页的时候直接克隆一个自己
final blockNode = clone();
blockNode.currentOffset = Offset(defaultDx, 0);
blockNode.children = children;
children = [];
return [blockNode];
}
Offset? nextChildOffset = Offset(defaultDx, defaultDy);
double unchanged = availableWidth;
if (children.isNotEmpty) {
int childIndex = 0;
//这里使用while而不是使用for去循环这个children的原因是需要避免在循环中修改了children长度的副作用
while (childIndex != children.length) {
ReaderNode child = children[childIndex];
//计算子节点剩余可使用的高度
//使用页面高度 - 当前节点的Y轴上的位置 - 当前节点(包含所有已处理的子节点)的高度
child.remainingHeight = NodeStatus.pageHeight - currentOffset.dy - currentHeight;
bool isFull = unchanged == availableWidth;//判断是否行首(意为判断是否为该行第一个节点)
child.isBranch = isBranch; //是否允许文本分行(这里是为了给例如Ruby标签这样的节点使用的)
//判断是块级节点还是其他节点
if (child is BlockNode) {
currentHeight += currentLineHeight; // 加上上一行的最终高度
currentLineHeight = 0;
// 块级节点Y轴从当前节点(这里指的是这个块级节点的父级)高度开始
nextChildOffset = Offset(defaultDx, offset.dy + currentHeight);
//因为是块级节点,所以可以直接那unchanged(最大宽度)来使用
truncatedNode = child.layout(unchanged, nextChildOffset);
currentHeight += child.currentHeight;
// 因为块级节点是独占的存在,不可能有其他节点会和块级节点在同一行的
// 所以可以直接清空currentLineHeight去给下一行做判断
currentLineHeight = 0;
} else {
truncatedNode = child.layout(availableWidth, nextChildOffset!, isFull: isFull);
//叠加计算这个行内的所有元素的宽度
currentLineWidth += child.currentWidth;
//判断当前行的高度和这个行内元素的高度,如果高度不同标记highlyInconsistent为true
if (child.currentHeight != currentLineHeight &&
currentLineHeight > 0 &&
!highlyInconsistent) {
highlyInconsistent = true;
}
//这里再货比同一行内的所有Node的高度,拿取最高的节点高度为当前行的高度
currentLineHeight =max(currentLineHeight, child.currentHeight);
//计算当前行的剩余可用宽度
availableWidth = availableWidth - child.currentWidth;
currentLineIndex.add(childIndex);
}
currentWidth = max(currentWidth, currentLineWidth);
//这里将该子节点含有所有的下标添加到当前节点的hasIndexList下,后续要做已看进度的跳转
//根据这个下标的值来跳转相应的页码
hasIndexList.addAll(child.hasIndexList);
if (child.isEnter || child.isTurning || availableWidth <= 0) {
currentHeight += currentLineHeight;
rearrangement();
currentLineWidth = 0;
currentLineHeight = 0;
currentLineIndex = [];
if (child.isTurning) {
//如果子节点的isTurning标记为true就代表从这个子节点开始需要分页了
//当前节点也标记为需要分页,向上传递
isTurning = true;
turning(childIndex);
break;
} else if (child.isEnter || availableWidth <= 0) {
//当子节点需要分行或者是当前剩余宽度已经不够用了
availableWidth = unchanged;
nextChildOffset = Offset(defaultDx, defaultDy + currentHeight);
childIndex++;
//往当前节点的字节插入一个新的分行后的节点
children.insertAll(childIndex, truncatedNode);
continue;
}
}
nextChildOffset = child.nextOffset ?? Offset(defaultDx, defaultDy);
childIndex++;
isOver = true;
}
rearrangement();
}
//处理最后一行的高度没有添加到当前的节点的高度上
if (currentLineHeight > 0) {
currentHeight += currentLineHeight;
currentLineHeight = 0;
}
//判断如果为块级元素则要加上这个外边距和内边距的实现
if (this is BlockNode) {
//判断isOver的原因是可能这个块级节点在这个页面装不下了,然后需要去到下一页
//那么当前页面的这个块级节点就不需要下边的边距了
if (isOver) {
currentHeight += (styleModel.padding?.bottom ?? 0);
currentHeight += (styleModel.margin?.bottom ?? 0);
}
}
nextOffset = nextChildOffset;
//truncatedIndex不为-1的时候说明当前页面是需要分页,所以直接裁断这个children
//这样在调用print方法绘制的时候就不会出现绘制多余的节点了
if (children.isNotEmpty && truncatedIndex != -1) {
children = children.sublist(0, truncatedIndex + 1);
}
return nextPageNode;
}
void turning(childIndex) {
isOver = false;
//拷贝一个当前节点,以维持原本的树形结构
final elementNode = clone();
//truncatedNode在上面循环的时候已经拿到了子节点layout方法返回出来的分页节点了
//所以在这里是直接调用addAll将childIndex以后的所有节点都放入这个truncatedNode中
truncatedNode.addAll(children.skip(childIndex + 1).toList());
elementNode.children = truncatedNode; //将truncatedNode当为这个拷贝节点的子节点
elementNode.currentOffset = Offset(defaultDx, 0);
truncatedIndex = childIndex;
nextPageNode = [elementNode];
}
void rearrangement() {
//这里是判断这个行内的所有节点高度是否相同,如果不相同的话可能会出现第一个节点比第二个节点矮一截的情况
//所以这里需要将这样的节点给重新编排一边
if (currentLineIndex.isNotEmpty && highlyInconsistent) {
for (int index in currentLineIndex) {
ReaderNode child = children[index];
if (child.currentHeight == currentLineHeight) continue;
double difference = currentLineHeight - child.currentHeight;
child.deepUpdateOffset(0, difference);
children[index] = child;
}
currentLineIndex.clear();
highlyInconsistent = false;
}
}
//递归绘制子节点
@override
void paint(Canvas canvas, Offset offset) {
if (children.isNotEmpty) {
for (ReaderNode child in children) {
child.paint(canvas, child.currentOffset);
}
}
}
}分页计算
到目前为止,已经完成了 EPUB 文件解析、CSS 样式解析 以及 节点树的生成。
其中 ElementNode 负责 布局处理,TextNode 负责 文本排版,但要实现阅读器的完整体验,还需要一个 分页器 来把整个章节拆分成可翻页的页面。
PageNodes 类
PageNodes 的职责是:
- 持有一个
List<List<ReaderNode>>,每个子List代表一页的节点树。 - 递归调用各个
ReaderNode的layout方法,实现分页逻辑。 - 计算并记录总页数、阅读进度。
核心流程:
- 遍历章节节点树
- 调用
layout获取排版结果 - 若节点超出当前页高度,则生成 spillover(溢出节点),放入下一页继续处理
- 最终得到一个 分页后的节点树集合
class PageNodes {
List<List<ReaderNode>> list = [];
int pageCount = 0;
int readRecodesIndex;
double pageHeight;
double pageWidth;
bool isColumn;
int columnNum;
List<List<ReaderNode>> unallocated;
int readPage = 0;
void _paginateChapter(List<ReaderNode> chapterRootNodes) {
NodeStatus.pageHeight = pageHeight;
NodeStatus.pageWidth = pageWidth;
List<ReaderNode> nodesToLayout = List.from(chapterRootNodes);
while (nodesToLayout.isNotEmpty) {
final List<ReaderNode> currentPageNodes = [];
List<ReaderNode> nodesForNextPage = [];
Offset currentOffset = Offset.zero;
for (int i = 0; i < nodesToLayout.length; i++) {
final node = nodesToLayout[i];
List<ReaderNode> spillover = node.layout(pageWidth, currentOffset);
currentPageNodes.add(node);
if (node.hasIndexList.contains(readRecodesIndex)) readPage = list.length + currentPageNodes.length;
if (spillover.isNotEmpty) {
nodesForNextPage.addAll(spillover);
if (i + 1 < nodesToLayout.length) {
nodesForNextPage.addAll(nodesToLayout.sublist(i + 1));
}
break;
}
currentOffset = node.nextOffset ?? const Offset(0, 0);
}
if (currentPageNodes.isNotEmpty) {
list.add(currentPageNodes);
} else if (nodesToLayout.isNotEmpty && nodesForNextPage.isEmpty) {
nodesForNextPage = List.from(nodesToLayout);
}
nodesToLayout = nodesForNextPage;
}
}
void _start() {
for (var item in unallocated) {
_paginateChapter(item);
}
pageCount = isColumn ? (list.length / columnNum).ceil() : list.length;
readPage = isColumn ? (readPage / columnNum).ceil() : readPage;
readPage = max(0, readPage - 1);
}
PageNodes(this.unallocated, this.pageWidth, this.pageHeight,
{this.isColumn = false, this.columnNum = 2, this.readRecodesIndex = 0}) {
_start();
}
}页面渲染
在完成分页后,得到的 PageNodes 数据即可直接用于 页面绘制。
这里使用 CustomPainter 循环绘制节点树,达到完整的阅读器渲染效果:
class ReaderPainter extends CustomPainter {
final List<ReaderNode> nodeList;
ReaderPainter(this.nodeList);
@override
void paint(Canvas canvas, Size size) {
for (ReaderNode node in nodeList) {
node.paint(canvas, node.currentOffset);
}
}
@override
bool shouldRepaint(covariant CustomPainter oldDelegate) => true;
}总结与展望
至此,一个简易 EPUB 阅读器的核心渲染引擎已经构建完成。整个流程自底向上,实现了从文件解析到最终绘制的完整闭环。
核心渲染流程总结
渲染引擎的实现可以概括为以下四个关键步骤:
解析:首先,对 EPUB 包内的 XHTML 内容进行 DOM 解析,同时解析 CSS 样式表,建立起内容与样式的初步映射关系。
节点树构建:将解析后的 DOM 和 CSS 数据,转换为一个自定义的、更适合渲染和排版的内部节点树结构(如
ReaderNode、ElementNode、TextNode)。这棵树是后续所有操作的基础。分页计算:这是实现阅读器翻页体验的核心。通过遍历节点树调用节点的
layout方法将节点分配到不同的页面(PageNodes),完成内容的分页。绘制:最后,利用 Flutter 的
CustomPaint,将计算好的页面节点(PageNodes)高效地绘制到屏幕画布上,最终呈现给用户。
通过上述流程,再配合 PageView 等翻页控件,一个基础的 EPUB 阅读体验便得以实现。
当前实现的局限与未来展望
尽管核心功能已经完成,但当前的渲染器仍处于早期阶段,存在一些局限性,也为未来的迭代指明了方向:
标签兼容性有限:目前仅实现了对部分常用 HTML 标签的支持。若要完美兼容所有 EPUB 文件,需要持续扩展和完善对更多标签(如表格、复杂列表、多媒体等)的解析与渲染。
导航与定位机制:当前的阅读进度记录和跳转功能采用了较为取巧的临时方案。未来可以升级为遵循 EPUB 官方
CFI (Canonical Fragment Identifier)规范的方式,实现更精准、更具通用性的书签和跳转功能。性能优化:对于包含大量图片或复杂样式的书籍,分页计算和绘制的性能仍有提升空间。可以探索更优的算法、懒加载或缓存策略来提升大型书籍的加载速度和翻页流畅度。
功能扩展:在现有基础上,未来还可以添加更多高级功能,如:全文搜索、文本高亮与笔记、主题切换、字体设置等,从而打造一个功能更全面、体验更完善的 EPUB 阅读器。
感谢您一路看到这里,以上就是我构建这个 EPUB 阅读器核心引擎的完整心路历程和技术总结。这个项目目前仍处于初级阶段,有许多可以完善和探索的地方,希望我的分享能起到抛砖引玉的作用。期待与您在未来的开发中进一步交流探讨。